更新升级指南
本指南将帮助您完成系统的更新升级操作,包括在线升级和手动升级两种方式,并提供常见问题的解决方案。
更新操作
⚠️ 警告
- 重要提示:更新前请务必备份数据库和源码目录,防止更新失败!
- 重要提示:更新前请务必备份数据库和源码目录,防止更新失败!
- 重要提示:更新前请务必备份数据库和源码目录,防止更新失败!
方式 1:在线升级
适用条件
- 未进行二次开发或改变目录结构。
- 必须逐个版本升级。
操作步骤
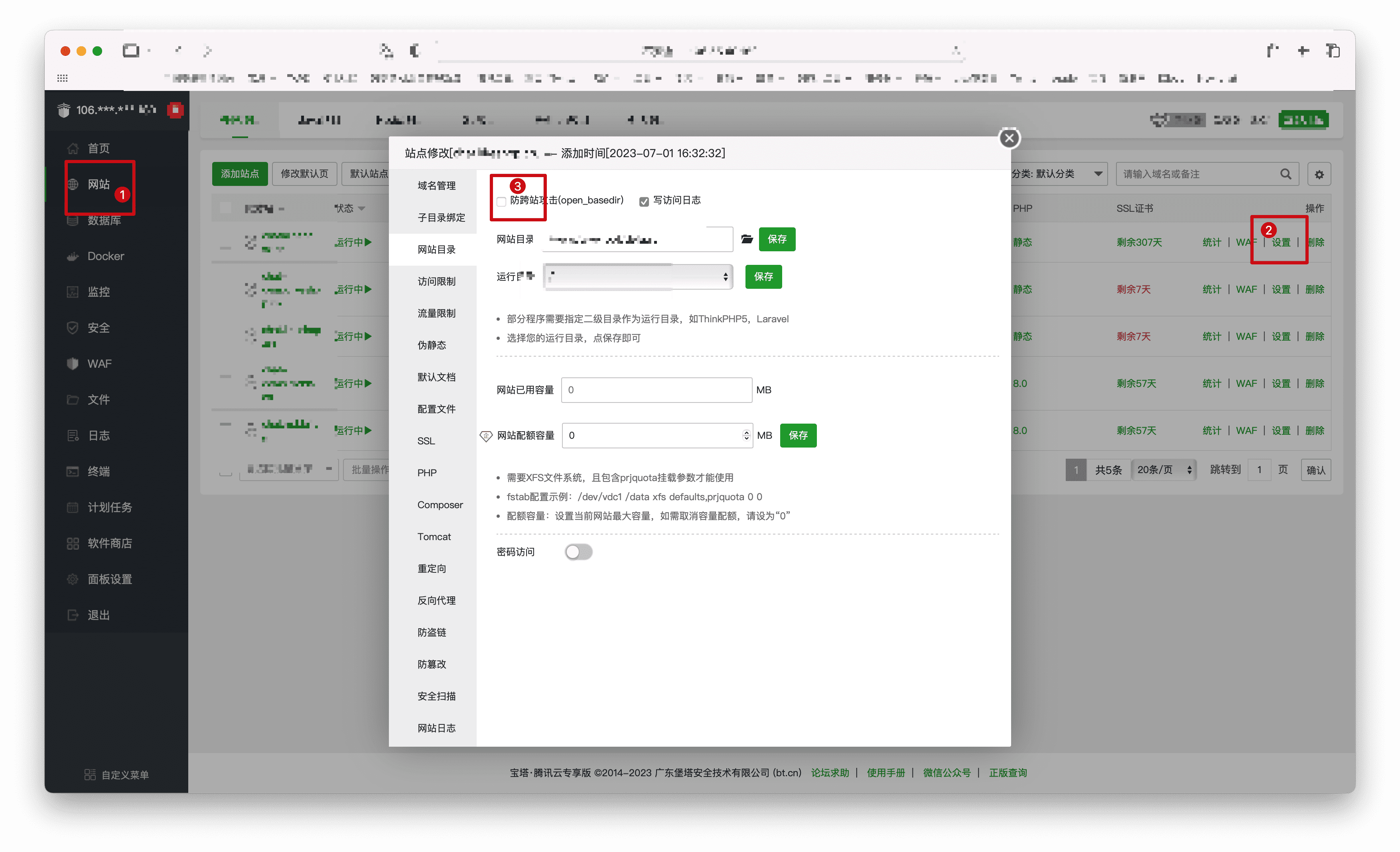
关闭防跨站攻击:
- 登录宝塔面板,点击【网站列表】,选择项目网站【设置】->【网站目录】,临时去掉【防跨站攻击(open_basedir)】。
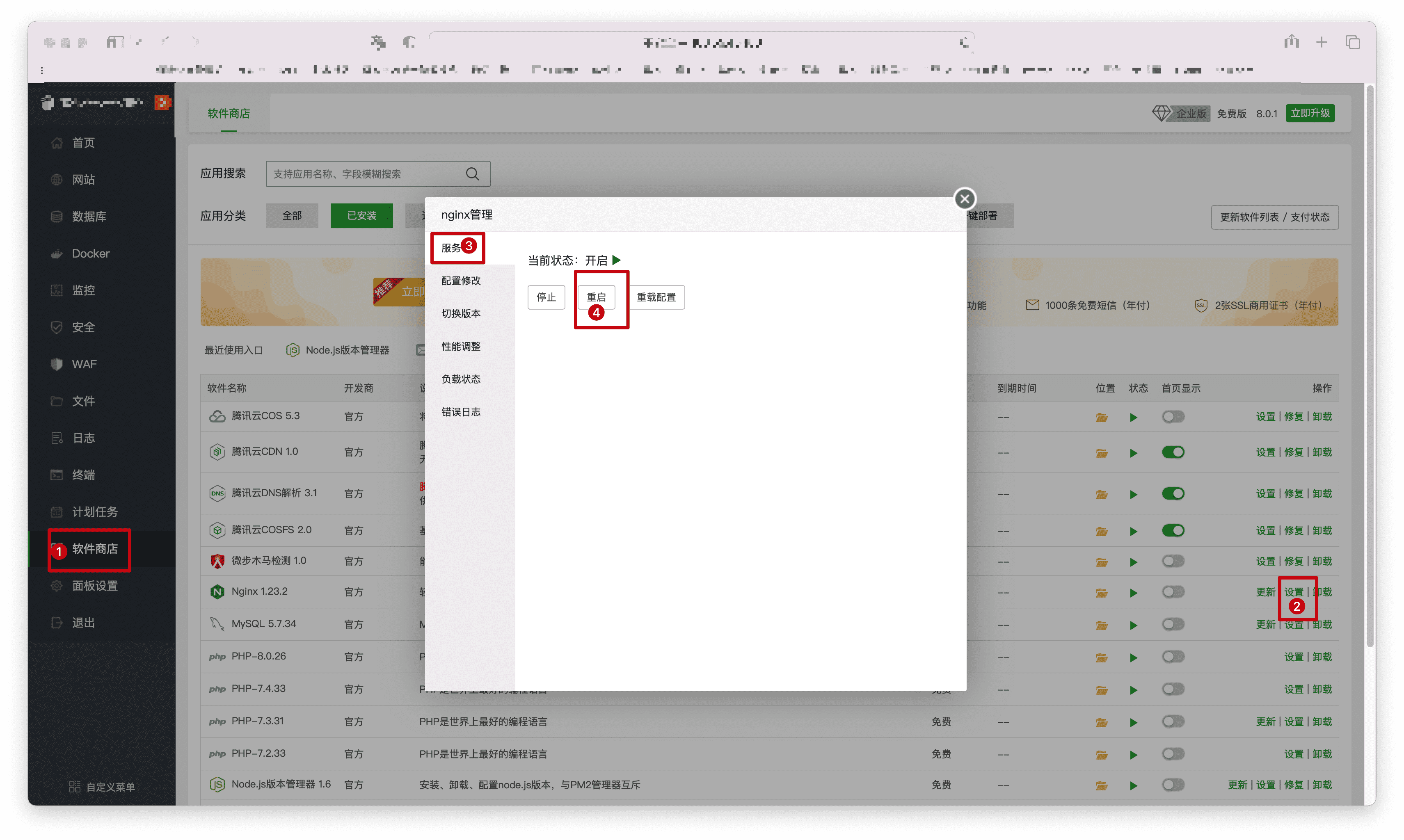
重启 Nginx:
- 点击【软件商店】,找到 Nginx,选择【设置】->【重启】。
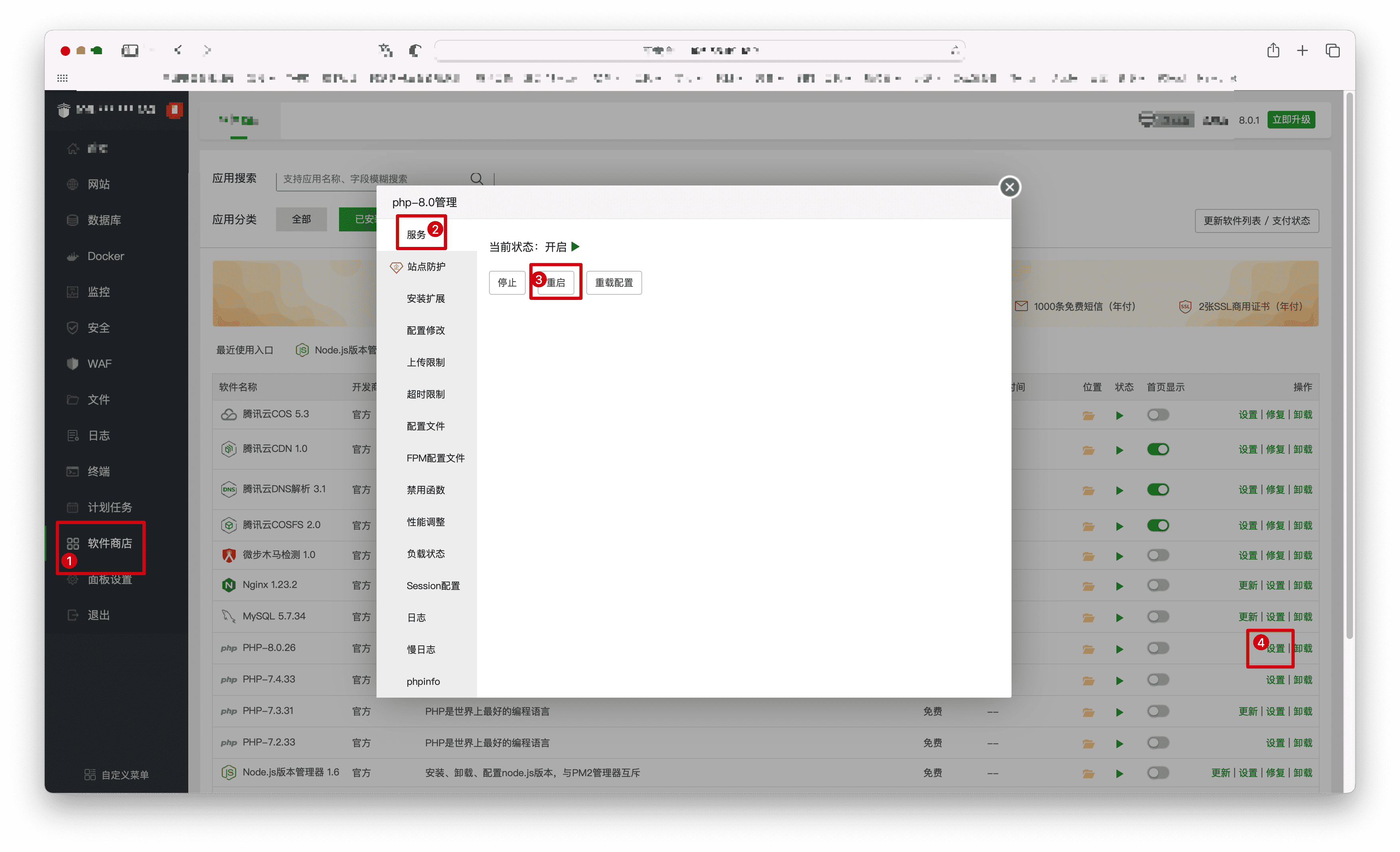
重启 PHP:
- 点击【软件商店】,找到 PHP-8.0,选择【服务】->【重启】。
在线更新:
- 登录后台,点击【系统设置】->【系统维护】->【系统更新】,点击【一键更新】。
恢复防跨站攻击:
- 更新完成后,重新开启【防跨站攻击(open_basedir)】。
清理缓存:
- 登录后台,点击【系统设置】->【系统维护】->【系统缓存】->【清理缓存】。
重新发布小程序:
- 更新后,小程序需要重新发布。
方式 2:手动升级到最新版本
操作步骤
备份关键文件:
- 备份原项目的以下文件:
server/.envserver/config/install.lockserver/public/uploadsserver/license/my.license
- 备份原项目的以下文件:
替换源码:
- 下载最新的源码包,删除原项目的
server目录,替换为源码包中的server目录。 - 将备份的文件还原到对应的位置。
- 下载最新的源码包,删除原项目的
更新数据库结构:
- 如果正式上线的项目数据表前缀不是
ai_,需将like.sql中的前缀替换为实际前缀。 - 在本地或线上新建一个数据库,导入
like.sql。 - 使用工具(如 Navicat)同步新数据库的数据结构到线上项目。
- 如果正式上线的项目数据表前缀不是
更新常见问题
1. 在线升级提示未授权
① IP 未授权
- 联系客服获取授权文件证书 上传文件到指定文件目录内
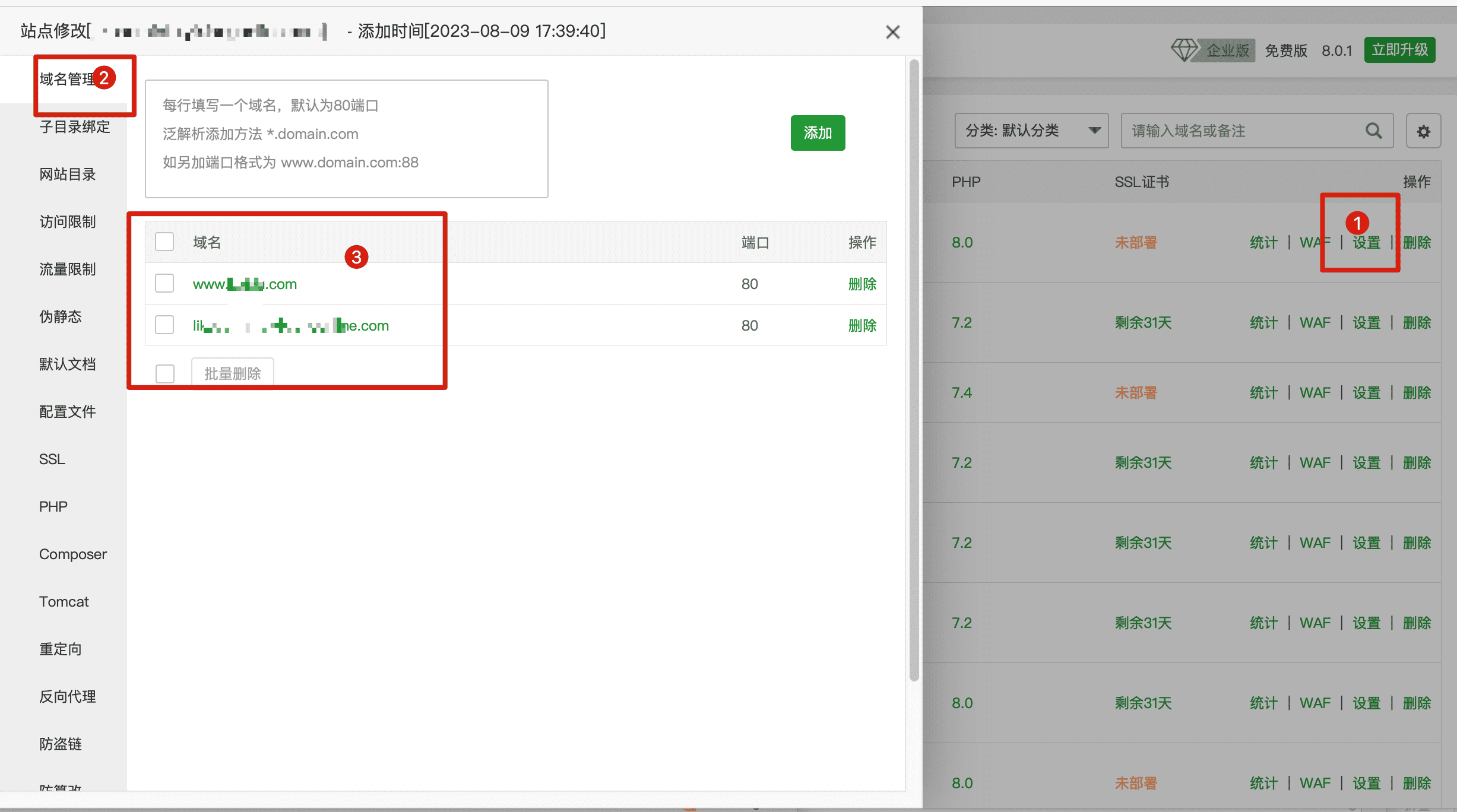
② 域名未授权
- 如果站点配置了多个域名,授权文件只支持单域名。删除未授权的域名即可。
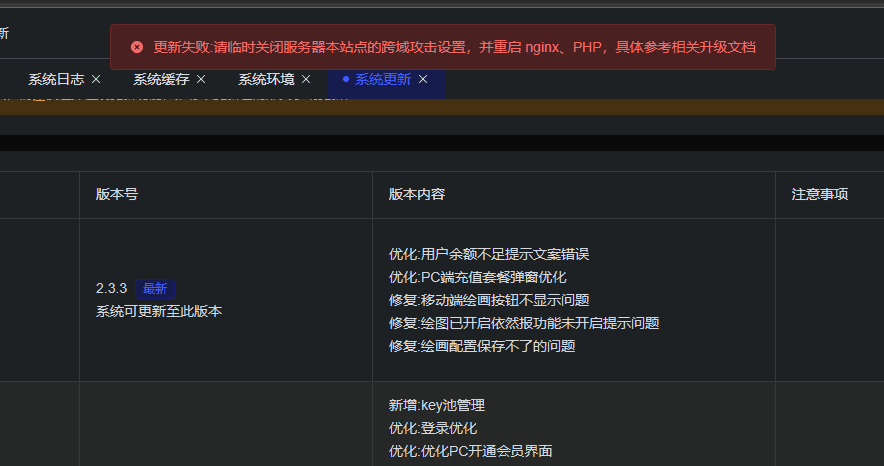
2. 在线升级失败的其他原因
① 提示关闭跨域攻击
- 确保已关闭防跨站攻击,并重启 Nginx 和 PHP。
② 出现 500 错误
- 目录结构改变:二开或目录结构改变会导致无法升级。
- 目录权限不足:确保项目目录权限设置为
www用户。 - 缺少 ZipArchive:确保 PHP 已安装
ZipArchive扩展。 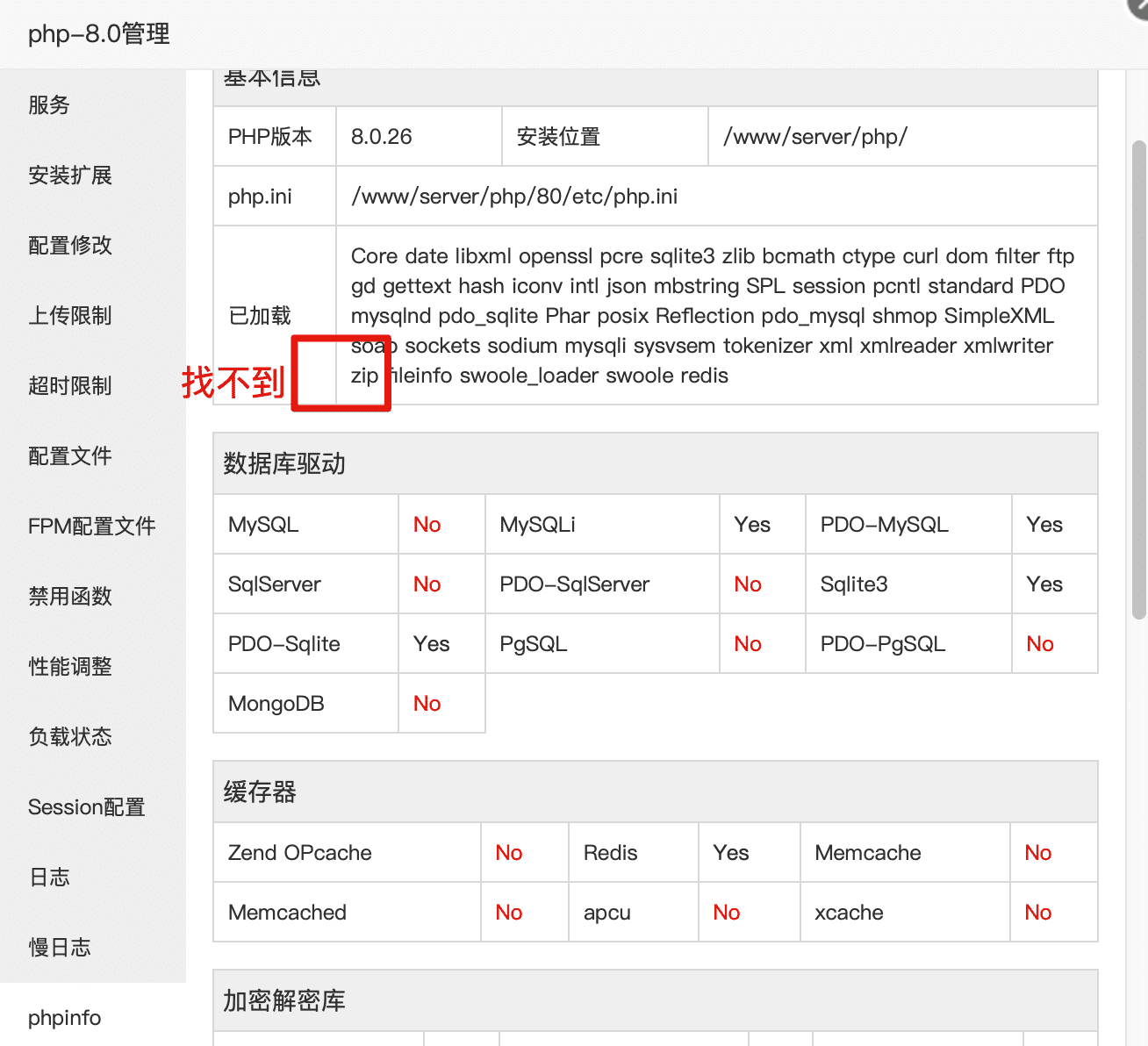
老版本必做
安装配置 Redis
安装 Redis:
- 在宝塔面板中安装 Redis 和 PHP 的 Redis 扩展。
配置 Redis:
- 打开
server/.env文件,添加以下配置:plaintext[QUEUE] NAME = chatai HOST = 127.0.0.1 PORT = 6379 PASSWORD =
- 打开
版本更新注意事项
3.3.0 版本
- 确保已配置 Redis,未配置请参考上文。
3.4.0 版本
- 参考部署文档设置守护进程。
3.5.0 版本
- 执行数据迁移脚本:访问
https://(你的域名)/migration。 - 重新编译并提交小程序。
3.6.0 版本
- Gemini 模型需设置反向代理。
- SD 绘图需本地部署,并添加守护进程。
至此更新升级完成
通过以上步骤,您可以顺利完成系统的更新升级操作。如有任何问题,请参考相关文档或联系技术支持。